
Ein Überblick über eine Auswahl an wissenschaftlichen KI-Projekten, die derzeit im Rahmen von BayernKI durchgeführt werden:
Center: NHR@FAU
The LSS specializes in the modeling and massive-scale numerical simulation of complex physical systems, ranging from fluid dynamics to particle mechanics. This bridges the gap between advanced numerical algorithms and practical high-performance computing (HPC). Leveraging recent advancements in AI we also started to integrate deep learning into traditional simulation pipelines, e.g. by developing robust surrogate models for specific problem scopes and embedding learnable components directly into multi-purpose numerical codes.
Project: Surrogate Models and Hybrid Solvers for CFD
Project description: This project integrates machine learning with classical Computational Fluid Dynamics (CFD). We perform a systematic benchmark of Fourier Neural Operators (FNO) and U-Net based surrogates across laminar, transitional, and turbulent flow regimes, utilizing a physically verified dataset containing high-fidelity timesteps, averaged fields, and aerodynamic forces. To merge these paradigms, we are developing an infrastructure for in-memory access and concurrent scheduling of Python (ML) and C++ (HPC) applications. This groundwork serves a step towards online training, the continuous model training alongside running simulations to develop fundamental models that generalize better as well as hybrid solvers, implementing learned components inside of solvers to enhance our numerical simulations.
Center: NHR@FAU
Researchers and students at the Pattern Recognition Lab (LME) develop and implement algorithms for recognizing, classifying, and analyzing patterns in data such as images, signals, and speech. Our research is largely interdisciplinary and has a strong focus on applications in medical and health engineering. As a research group working on machine learning, image analysis, and signal processing, we aim to connect methodological progress in AI with practical impact. The lab maintains close national and international collaborations with universities, research institutes, and industrial partners, supporting research that is both scientifically rigorous and relevant to real-world settings.
Project: Zero-Shot Paragraph-Level Handwriting Imitation
Project description: This project develops a paragraph-level handwriting imitation system for preserving personal writing style in digital communication. Using conditional latent diffusion models, high-resolution handwriting is generated from a style sample and target text in a compact latent space, enabling efficient and scalable synthesis. The method supports zero-shot generalization to unseen writers and enables coherent, style-consistent paragraph generation for applications such as personalized messaging and style-preserving text rendering.
Project: BraTS Pathology Challenge (Glioma Subregion Classification)
Project description: This project focuses on classifying glioma tumor subregions within the BraTS Lighthouse 2025 Pathology Challenge, addressing the heterogeneous histological structure brain tumors. It uses foundation models for feature extraction, and XGBoost as the final classifier to model complex intra-tumoral variability. The approach achieved 1st place in the MICCAI BraTS-Lighthouse 2025 Challenge (Task 10: heterogeneous histological landscape of gliomas), demonstrating the effectiveness of combining foundation-model features with classical machine learning for computational pathology.
Pilot Projects 2025
Project Manager: Christian Jaumann
Principal Investigator: Prof. Dr. Annemarie Friedrich
Affiliation: University Augsburg
HPC Platform used: NHR@FAU: Alex GPU cluster
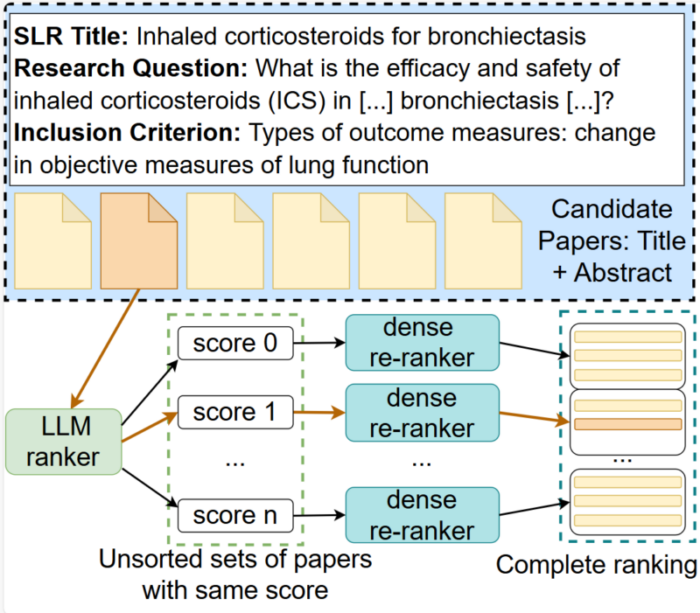
The scientific literature is growing rapidly on a daily basis, making it hard to keep track of the state-of-the-art. Systematic literature reviews (SLRs) aim to identify and evaluate all relevant literature on a topic. After retrieving a set of candidate papers, the abstract screening phase determines initial relevance according to a set of criteria. Large Language Models (LLMs) provide strong text interpretation skills, but are not naturally suited for creating ranked lists of large sets of documents due to scalability issues. We combine LLM-based relevance judgments with neural dense re-rankers for abstract screening, outperforming existing ranking systems on the task by a large margin.
Project Manager: Shuo Chen
Principal Investigator: Prof. Dr. Volker Tresp
Affiliation: Tresp Lab, Institute of Informatics, LMU Munich
HPC Platform used: LRZ AI Systems
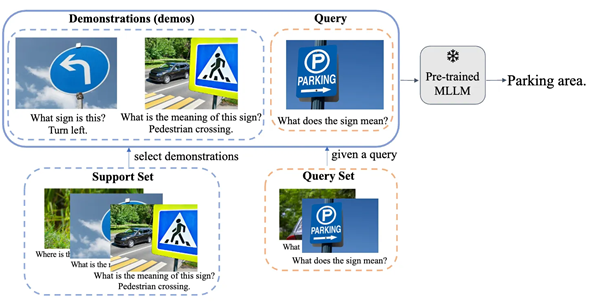
This project investigates how vision-language models (VLMs) actually exploit the “few-shot” demonstrations they are given. Using representative open-source Flamingo-style VLMs and eight benchmarks (VQA, captioning, classification and reasoning), the authors dissect two core variables: demo content (image vs. text) and demo selection strategy.
Systematic ablations show that the models’ gains from in-context learning are driven almost entirely by the textual portion of each demonstration; replacing the accompanying images with blanks, noise or mismatched pictures produces negligible drops in accuracy, whereas corrupting the demo text severely degrades performance. Analysis of the masked cross-attention mechanism explains why: during generation the model attends only to visual tokens from the current query image, so visual features from earlier demos cannot directly influence predictions, while their texts propagate through self-attention.
Building on this insight, the paper introduces Mixed-Modality In-Context Example Selection (MMICES). MMICES first filters candidate demos using visual similarity to the query, then reranks them with textual similarity, ensuring that the few examples fed to the model are jointly relevant in both modalities. Despite its simplicity, MMICES boosts VLM accuracy by up to 4.2 points and narrows the gap between purely textual and multimodal prompting across tasks, offering a lightweight recipe for more reliable multimodal ICL.

Principal Investigator: Prof. Dr. Josif Grabocka
Affiliation: University of Technology Nuremberg
HPC Platform Used: Alex GPU cluster (NHR@FAU)
In this project, we developed Efficient Cross-Episodic Transformers (ECET), a new algorithm for online Meta-Reinforcement Learning that addresses the challenge of enabling reinforcement learning agents to perform effectively in previously unseen tasks. We demonstrate how past episodes serve as a rich source of in-context information, which our model effectively distills and applies to new contexts. Our learned algorithm is capable of outperforming the previous state-of-the-art and provides more efficient meta-training while significantly improving generalization capabilities. Experimental results, obtained across various simulated tasks of the MuJoCo, Meta-World, and ManiSkill benchmarks, indicate a significant improvement in learning efficiency and adaptability compared to the state-of-the-art. Our approach enhances the agent’s ability to generalize from limited data and paves the way for more robust and versatile AI systems.

Project Manager: Johannes Schusterbauer-Fischer
Principal Investigator: Prof. Dr. Björn Ommer
Affiliation: Ludwig Maximilian University Munich (LMU Munich)
HPC Platform Used: Alex GPU cluster (NHR@FAU)
Visual synthesis has recently seen significant leaps in performance, largely due to breakthroughs in generative models. Diffusion models have been a key enabler, as they excel in image diversity. However, this comes at the cost of slow training and synthesis, which is only partially alleviated by latent diffusion. To this end, flow matching is an appealing approach due to its complementary characteristics of faster training and inference but less diverse synthesis. We demonstrate that introducing flow matching between a frozen diffusion model and a convolutional decoder enables high-resolution image synthesis at reduced computational cost and model size. A small diffusion model can then effectively provide the necessary visual diversity, while flow matching efficiently enhances resolution and detail by mapping the small to a high-dimensional latent space. These latents are then projected to high-resolution images by the subsequent convolutional decoder of the latent diffusion approach.
Combining the diversity of diffusion models, the efficiency of flow matching, and the effectiveness of convolutional decoders, state-of-the-art high-resolution image synthesis is achieved at 1K and 2K resolution with minimal computational cost. Importantly, our approach is orthogonal to recent approximation and speed-up strategies for the underlying model, making it easily integrable into the various diffusion model frameworks.
Principal Investigator: Prof. Dr. Josif Grabocka
Affiliation: University of Technology Nuremberg
HPC Platform Used: Alex GPU cluster (NHR@FAU)
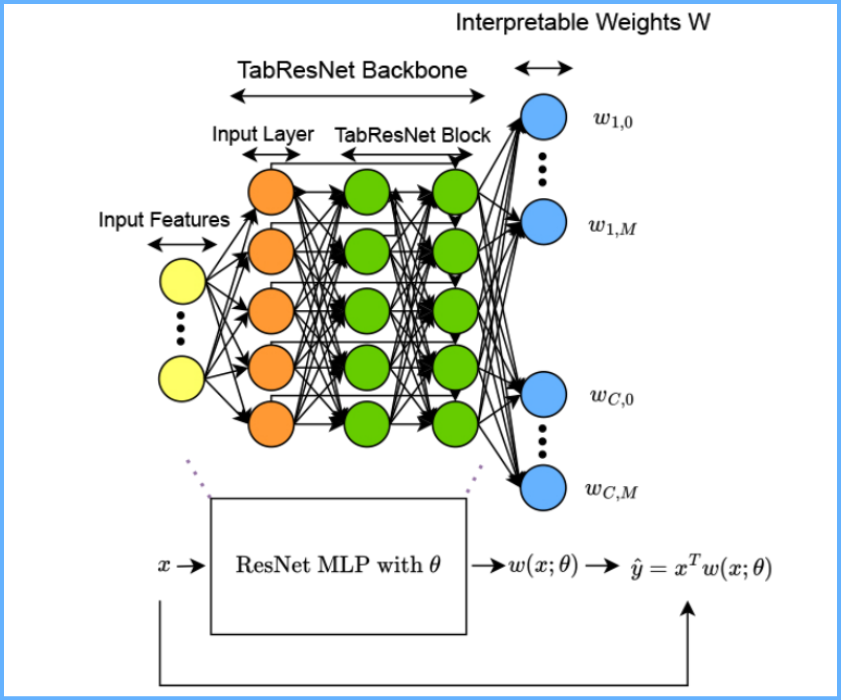
Even though neural networks have been long deployed in applications involving tabular data, still existing neural architectures are not explainable by design. In this project, we developed a new class of interpretable neural networks for tabular data that are both deep and linear at the same time (i.e. mesomorphic). We optimize deep hypernetworks to generate explainable linear models on a per-instance basis. As a result, our models retain the accuracy of black-box deep networks while offering free-lunch explainability for tabular data by design. Through extensive experiments, we demonstrate that our explainable deep networks have comparable performance to state-of-the-art classifiers on tabular data and outperform current existing methods that are explainable by design.

Project Manager: Jan Pfister, Julia Wunderle
Principal Investigator: Prof. Dr. Andreas Hotho
Affiliation: Julius-Maximilians University Of Würzburg (JMU)
HPC Platform used: Alex GPU cluster (NHR@FAU)
We create two German-only decoder models, LLäMmlein 120M and 1B, transparently from scratch and publish them, along with the training data, for the German NLP research community to use. The model training involved several key steps, including extensive data preprocessing, the creation of a custom German tokenizer, the training itself, as well as the evaluation of the final models on various benchmarks. Throughout the training process, multiple checkpoints were saved and analyzed using the SuperGLEBer benchmark to monitor the models‘ learning dynamics. Compared to state-of-the-art models on the SuperGLEBer benchmark, both LLäMmlein models performed competitively, consistently matching or surpassing models with similar parameter sizes. The results show that the models‘ quality scales with size as expected, but performance improvements on some tasks plateaued early, offering valuable insights into resource allocation for future model development.
Project Manager: Franziska Weindel
Principal Investigator: Prof. Dr. Reinhard Heckel
Affiliation: Technical University of Munich (TUM)
HPC Platform used: LRZ AI Systems
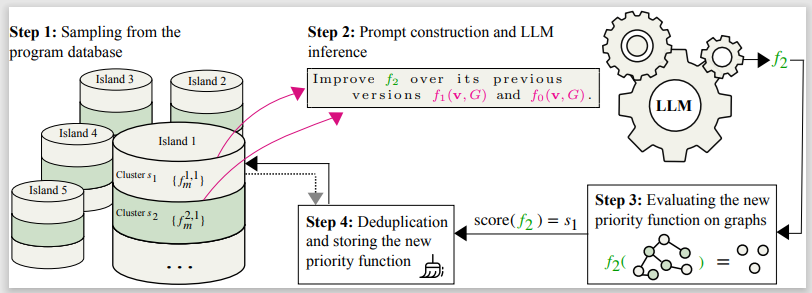
Traditionally, challenging algorithmic problems have been addressed using expert-designed solutions. Recent work, such as AlphaEvolve, has shown that large language models (LLMs) combined with evolutionary search can discover new algorithms for such problems. We consider an important, 70-year-old open problem in information theory: designing large deletion-correcting codes, which are sets of sequences that remain distinguishable after a fixed number of deletions. Our method uses an LLM-guided evolutionary search to discover new error-correcting codes. In some regimes, our search discovers entirely new constructions that outperform the best-known codes. In others, it rediscovers conjectured optimal code constructions. These results demonstrate the potential of LLM-guided search for solving challenging problems in information theory.
Project Manager: Dr. Michael Heinzinger
Principal Investigator: Prof. Dr. Burkhard Rost
Affiliation: Technical University of Munich (TUM)
HPC Platform Used: Cerebras CS-2 (LRZ)
Proteins—the essential building blocks of life—are composed of roughly 20 amino acids, yet deciphering how their sequences determine structure and function remains a complex challenge, especially given the vast volumes of data in biological databases.
Researchers at the Rost Lab (TUM), in partnership with the Leibniz Supercomputing Centre (LRZ), are using artificial intelligence, specifically language models, to crack the protein code more efficiently. Drawing an analogy between proteins and human language—where amino acids act like letters forming “sentences”—they developed SeqVec, based on the ELMo model, which processes protein sequences directly rather than relying on database pattern searches.
They then advanced to transformer-based models such as ProtTrans, trained on LRZ’s powerful GPU clusters. Most recently, the team has leveraged the Cerebras CS-2 system at LRZ, a novel AI architecture with massive memory and compute capabilities. This system simplifies distributed training and accelerates processing—enabling the training of highly complex models like ProtT5, which contains 3 billion parameters, compared to SeqVec’s 93 million.
The result: These large-scale language models can uncover the “syntax” and “grammar” of protein structures, revealing how proteins fold, function, and interact. This opens new pathways for designing drugs, biofuels, plastic-degrading materials, carbon-binding compounds, and other bespoke biomolecules. As model training and deployment evolve, language models could become vital tools across biotechnology, pharmacology, and medical research.
Get more information here.

Project Managers: Katharina Winter & Erik Schütz
Principal Investigator: Prof. Dr. Fabian Flohr
Affiliation: University of Applied Sciences Munich (HM)
HPC Platform Used: Alex GPU cluster (NHR@FAU)
Generative models are increasingly used in Autonomous Driving applications to improve decision-making, safety, and generalization to unseen scenarios and corner cases. At the Intelligent Vehicles Lab, we focus on Encoder-Decoder architectures and Large Language Models to enhance prediction and planning in urban driving environments and simulations. Powered by NHR, our research develops solutions that help autonomous systems navigate complex, real-world situations while making Autonomous Driving more explainable, ensuring trustworthiness and interpretability. As part of the nxtAIM project, a nationwide initiative focusing on Generative AI for Autonomous Driving, we contribute to shaping the future of AI in Germany.

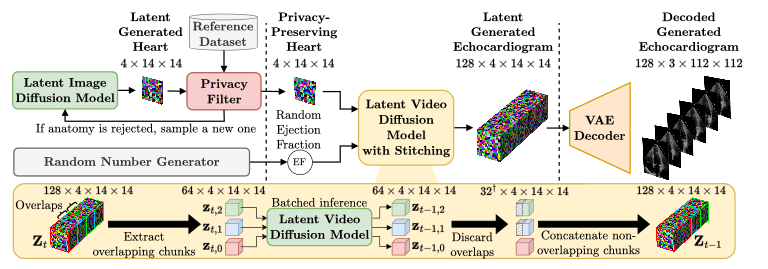
Project Manager: Hadrien Reynaud, Mischa Dombrowski
Principal Investigator: Prof. Dr. Bernhard Kainz
Affiliation: Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU)
HPC Platform used: Alex GPU cluster (NHR@FAU)
Medical datasets are often inaccessible due to intellectual property constraints and legal safeguards protecting patient privacy. We believe synthetic datasets could be a solution and extend the promising concept of generative models with formal privacy guarantees to an unprecedented scale by developing the most advanced video generative model for ultrasound video. Our approach synthesises cardiac ultrasound sequences that are virtually indistinguishable from real data, yet fully preserve patient confidentiality. Crucially, the generated datasets contain enough information diversity to train downstream models that reach the performance of models trained on genuine clinical data. Although synthetic data augmentation has been explored in large language models, this is the world first demonstration of it in computer vision — particularly for medical video applications. Specifically, we train latent flow matching models with Transformers or U-Net backbones, with sizes ranging from 30M to 500M parameters. Our findings reveal strong adherence to scaling laws, and demonstrates that once a model capacity surpasses a critical threshold, the resulting synthetic samples exhibit sufficient diversity and realism to enable state-of-the-art performance in downstream tasks without using any authentic patient data. This work paves the way for broadening research access to medical imaging while rigorously upholding privacy standards.

Project Manager: Tanveer Hannan
Principal Investigator: Dr. Thomas Seidl
Affiliation: Ludwig Maximilian University of Munich (LMU Munich)
HPC Platform used: Alex GPU cluster (NHR@FAU)
Large Language Models (LLMs) are continuously improving in handling text, but Vision-Language Models (VLMs) struggle with long videos, particularly for temporal reasoning. Existing VLMs downsample frames and lose temporal details, limiting temporal event comprehension. We introduce ReVisionLLM, a recursive vision-language model inspired by human search strategies. Our model identifies broad segments of interest and progres-sively refines focus to pinpoint precise temporal boundaries. This approach enables seamless handling of video durations ranging from minutes to hours. Additionally, our hierarchical training strategy starts with short clips to capture distinct events before scaling to longer videos. ReVisionLLM is the first VLM designed for hour-long video temporal event localization.
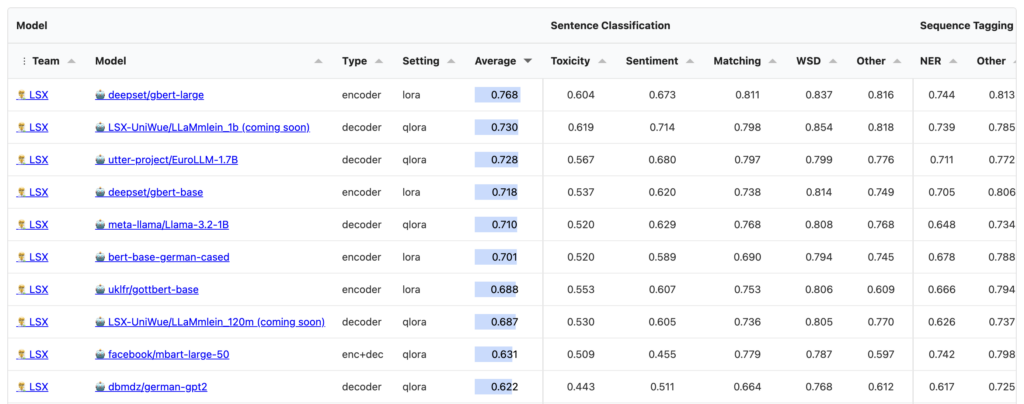
Project Manager: Jan Pfister
Principal Investigator: Prof. Dr. Andreas Hotho
Affiliation: Julius-Maximilians University Würzburg (JMU)
HPC Platform used: Alex GPU cluster (NHR@FAU)
Large Language Models (LLMs) are continuously being developed and improved, and there is no shortage of benchmarks that quantify how well they work; LLM benchmarking is indeed a long-standing practice, especially in the NLP research community. However, the majority of these benchmarks are not designed for German-language LLMs. We assembled a broad Natural Language Understanding benchmark suite for the German language and evaluated a wide array of existing German-capable models. This allows us to comprehensively chart the landscape of German LLMs.